The rise of AI detection
As AI-generated text floods the internet, universities, publishers, and platforms have deployed AI detection tools. These tools — including GPTZero, Originality.ai, and Turnitin's AI detection — claim to identify whether text was written by a human or generated by a language model. But how accurate are they, really? And what signals do they actually use?
The field has grown rapidly since large language models became widely available. Detection vendors continually update their models, and the research community is still debating how reliable these tools can fundamentally be — because, at their core, they are probabilistic classifiers, not forensic instruments. Understanding what they actually measure is the first step to putting their outputs in proper context.
Myth #1: AI detectors are near-perfect
Reality check: even well-regarded AI detectors produce false positives — cases where human-written text is incorrectly flagged as AI-generated. Academic researchers studying these tools consistently report non-trivial error rates, and the problem is particularly acute for non-native English writers, whose sentence patterns can statistically resemble AI output even when entirely original.
Detectors work on probabilities, not certainties. A high confidence score does not mean the text is definitely AI — it means the model estimates a high probability based on statistical patterns. This is a fundamental distinction that is often lost in how these tools are marketed and used. Several published studies have noted that certain populations of human writers face disproportionate false-positive rates (see References below).
There is also an adversarial dynamic: as detection methods become public, writing tools adapt, and the arms race continues. This means that any headline accuracy figure is likely to degrade over time as it becomes outdated.
Myth #2: AI detectors understand meaning
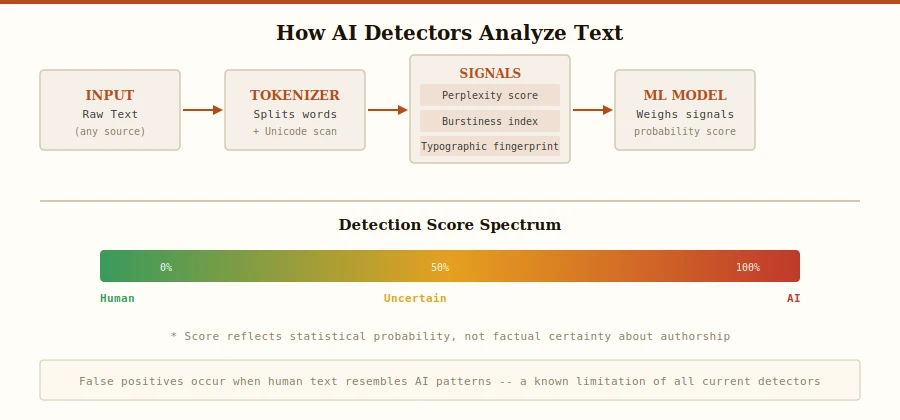
AI detectors do not "understand" text the way humans do. They analyze statistical patterns: how predictable each word is given the previous words (perplexity), how much sentence structure varies (burstiness), and what typographic symbols are present. A text with low perplexity — meaning it is highly predictable — is more likely to be flagged as AI-generated, regardless of its actual content quality or originality of ideas.
This has a counterintuitive implication: a very well-written, clear, and logically structured human essay might score higher on AI detection than a rambling, error-filled one. Clarity and consistency, ironically, are statistical signatures of AI text. Some researchers have pointed out that this creates a potential chilling effect on professional and academic writing, where clarity is a virtue.
Myth #3: Typographic symbols don’t matter
This is one of the most overlooked factors in AI detection. Detectors do not just look at words — they inspect the actual Unicode characters. An em dash (—, U+2014) is a different code point from a hyphen (-). Curly quotes (“”) differ from straight quotes (""). A Unicode ellipsis (…, U+2026) is a single character, not three periods.
These differences create detectable patterns because most humans typing casually on a keyboard do not naturally produce these typographic characters — they require deliberate effort or a specialized text processor. AI language models, however, are trained on large corpora of professionally typeset text where these characters appear frequently. As a result, AI-generated text tends to be rich in these Unicode symbols, making them a measurable signal.

In informal testing across various texts, replacing typographic symbols in AI-generated content with their plain ASCII equivalents can meaningfully reduce detection scores — though the effect varies by detector and text. Combined with other humanization techniques, typography normalization is one of the more tractable first steps, precisely because it targets a concrete, machine-readable signal rather than something abstract like "voice."
What detectors actually measure
- Perplexity: How "surprised" a language model would be by each word. Human writing tends to have higher perplexity (more variation), while AI text is more predictable and uniform. Low perplexity is a core detection signal.
- Burstiness: The variation in sentence length and complexity. Humans naturally mix short punchy sentences with longer, more elaborate ones. AI often produces structurally uniform sentences. Low burstiness is flagged by many detectors.
- Typographic fingerprints: The presence of specific Unicode characters — em dashes, curly quotes, Unicode ellipses — that are statistically overrepresented in AI training data relative to casual human writing.
- Statistical oddities: Unusual word frequency distributions, rare token usage, and other mathematical patterns that deviate from typical human writing baselines.
- Coherence and consistency: Some detectors penalize unusually consistent paragraph structure or argument flow, which can indicate machine generation.
Detector comparison table
The major commercial detectors differ in methodology, pricing, and how they handle edge cases. The table below summarizes publicly stated features; independent accuracy varies by text type and evolves with model updates.
| Detector | Primary signals | Free tier | API access | Notable caveat |
|---|---|---|---|---|
| GPTZero | Perplexity, burstiness, sentence-level scoring | Yes | Yes | Higher false-positive rate on non-native English text (per independent studies) |
| Originality.ai | Perplexity, factual consistency, readability | No (credit-based) | Yes | Optimized for web content; less tested on academic prose |
| Turnitin AI | Perplexity, writing behavior patterns | Institution-only | No (LMS integration) | Results are advisory; Turnitin explicitly cautions against use as sole evidence |
| Sapling AI | N-gram probability, stylistic patterns | Yes (limited) | Yes | Can be sensitive to formal register even in human writing |
| Writer.com detector | Perplexity, token distribution | Yes | Yes | Primarily calibrated for marketing and business text |
Case study: what typography normalization does
To illustrate how typography affects detection, consider a short essay passage produced by a language model. The raw output contains em dashes, curly quotes, and a Unicode ellipsis — all standard in AI output. Run through a typical detector, the statistical fingerprint is strong.
After replacing only the Unicode symbols with plain ASCII equivalents (no other changes to words or structure), the typographic signal is removed. The passage is identical in meaning and wording; only the character-level encoding differs. The outcome is that one measurable signal — typographic fingerprinting — is eliminated, which generally reduces the overall detection score to some degree. The exact reduction varies by detector and text length.

This case study also illustrates the limits: typography normalization does not address perplexity or burstiness. For those signals, the underlying text structure needs to change — varying sentence length, reordering arguments, injecting deliberate imprecision where appropriate. Typography is the easiest layer to address systematically and automatically; the others require more editorial effort.
The bottom line
AI detectors are useful screening tools but not infallible judges. They measure statistical proxies for AI authorship, and those proxies have known failure modes. False positives are a documented problem, particularly for certain writing styles and non-native speakers. Detection scores should be treated as probabilistic signals, not verdicts.
Reducing detection scores requires a multi-layered approach: normalizing typography, varying sentence structure, adding minor imperfections, and injecting genuine human voice. These are not tricks — they are the same techniques that distinguish good, varied writing from the overly polished uniformity that characterizes much AI output.
Read our complete guide to typographic normalization — HumanType handles the typography layer, the rest is up to you.
Further reading & references
- Liang et al. (2023). "GPT detectors are biased against non-native English writers." Patterns, Cell Press. doi.org/10.1016/j.patter.2023.100779
- Sadasivan et al. (2023). "Can AI-Generated Text be Reliably Detected?" arXiv preprint. arxiv.org/abs/2303.11156
- Turnitin (2023). AI Writing Detection: Guidance for Educators. Turnitin LLC. turnitin.com/solutions/ai-writing
- Gehrmann et al. (2019). "GLTR: Statistical Detection and Visualization of Generated Text." ACL 2019. aclanthology.org/P19-3019