Рост AI-детекции
По мере того как ИИ-тексты заполняют интернет, университеты, издатели и платформы начали активно использовать инструменты для обнаружения ИИ. Такие сервисы, как GPTZero, Originality.ai и AI-детекция Turnitin, заявляют, что могут определить, написан ли текст человеком или сгенерирован языковой моделью. Но насколько они точны на самом деле и какие сигналы используют?
Эта область развивается стремительно. Разработчики детекторов постоянно обновляют свои модели, а исследователи продолжают дискутировать о том, насколько надёжными эти инструменты могут быть в принципе. В основе своей они являются вероятностными классификаторами, а не криминалистическими инструментами. Понять, что именно они измеряют, — первый шаг к правильной интерпретации их результатов.
Миф #1: точность детекторов близка к 100%
Реальность такова: даже хорошо известные детекторы ИИ дают ложные срабатывания — ситуации, когда написанный человеком текст ошибочно помечается как сгенерированный ИИ. Академические исследователи, изучающие эти инструменты, стабильно фиксируют ненулевые уровни погрешностей, причём проблема особенно остра для тех, кто пишет не на родном языке: их синтаксические паттерны могут статистически напоминать ИИ-вывод, даже будучи полностью оригинальными.
Детекторы работают с вероятностями, а не с достоверностями. Высокий показатель уверенности не означает, что текст точно написан ИИ, — это лишь означает, что модель оценивает высокую вероятность на основе статистических паттернов. Это принципиально разные вещи, которые нередко теряются в маркетинговых заявлениях разработчиков. В ряде опубликованных исследований отмечается, что определённые группы авторов непропорционально часто сталкиваются с ложными срабатываниями (см. раздел «Источники» ниже).
Существует также противостояние разработчиков: по мере того как методы детекции становятся известны, инструменты написания адаптируются, и гонка продолжается. Это означает, что любые громкие заявления о точности со временем устаревают.
Миф #2: детекторы ИИ понимают смысл текста
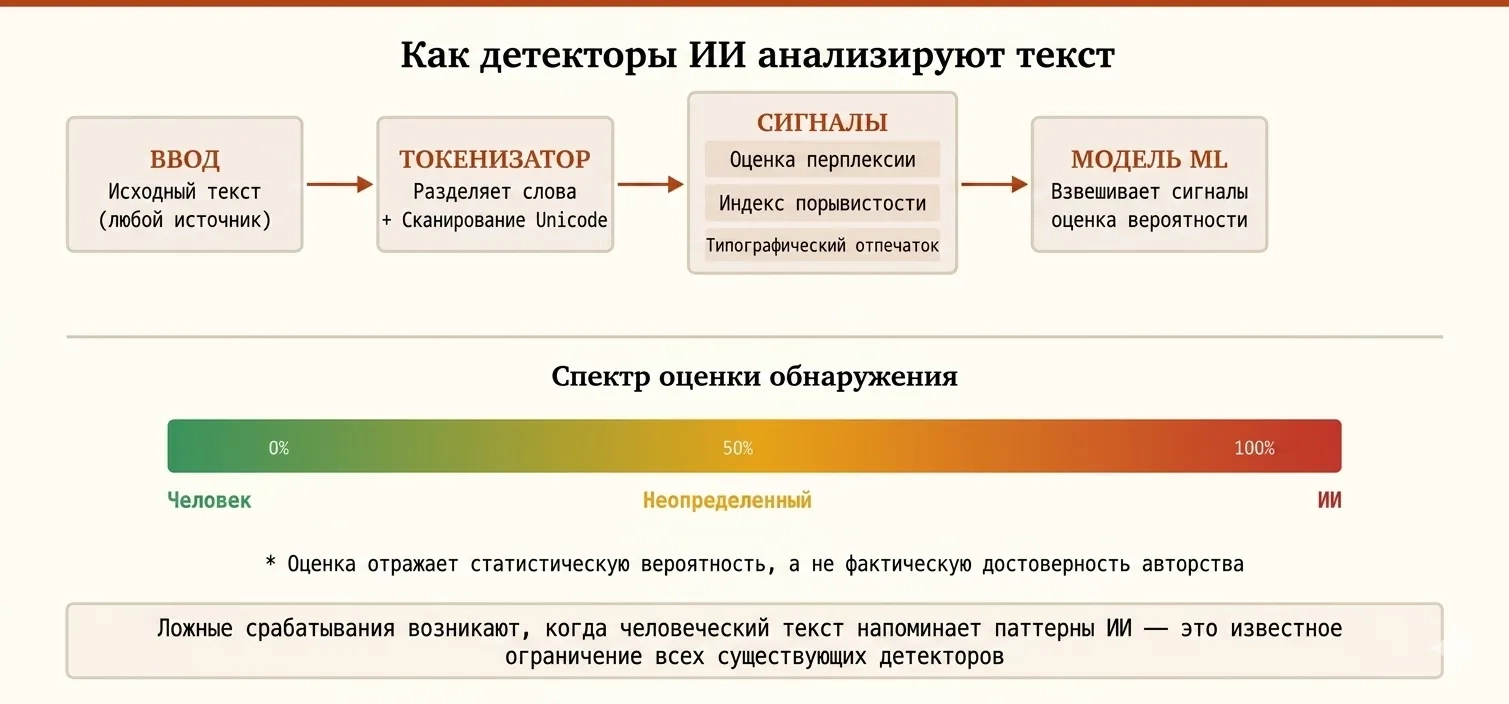
Детекторы ИИ не «понимают» текст так, как это делает человек. Они анализируют статистические паттерны: насколько предсказуемо каждое слово с учётом предыдущих слов (перплексия), насколько варьируется структура предложений (бёрстинесс) и какие типографские символы присутствуют. Текст с низкой перплексией — то есть высокопредсказуемый — с большей вероятностью будет помечен как ИИ-текст, независимо от качества его содержания или оригинальности идей.
Это имеет неочевидное следствие: очень хорошо написанное, чёткое и логически структурированное человеческое эссе может набрать более высокий балл AI-детекции, чем сбивчивый, изобилующий ошибками текст. Ясность и последовательность — как ни парадоксально — являются статистическими признаками ИИ-текста. Некоторые исследователи указывают, что это создаёт потенциальный сдерживающий эффект в отношении профессионального и академического письма, где ясность является добродетелью.
Миф #3: типографские символы не имеют значения
Это один из самых недооценённых факторов. Детекторы ИИ смотрят не только на слова — они инспектируют реальные коды Unicode-символов. Длинное тире (—, U+2014) — это другой символ в кодировке, нежели дефис (-). Фигурные кавычки (“”) отличаются от прямых (""). Символ многоточия Unicode (…, U+2026) — это единственный символ, а не три точки.
Эти различия создают обнаруживаемые паттерны, потому что большинство людей, набирающих текст на клавиатуре, не производят эти типографские символы естественным образом — для этого требуются специальные действия или текстовый редактор с автозаменой. Языковые модели, напротив, обучены на огромных корпусах профессионально свёрстанных текстов, где эти символы встречаются часто. В результате ИИ-тексты, как правило, изобилуют этими Unicode-символами, что делает их измеримым сигналом для детекторов.
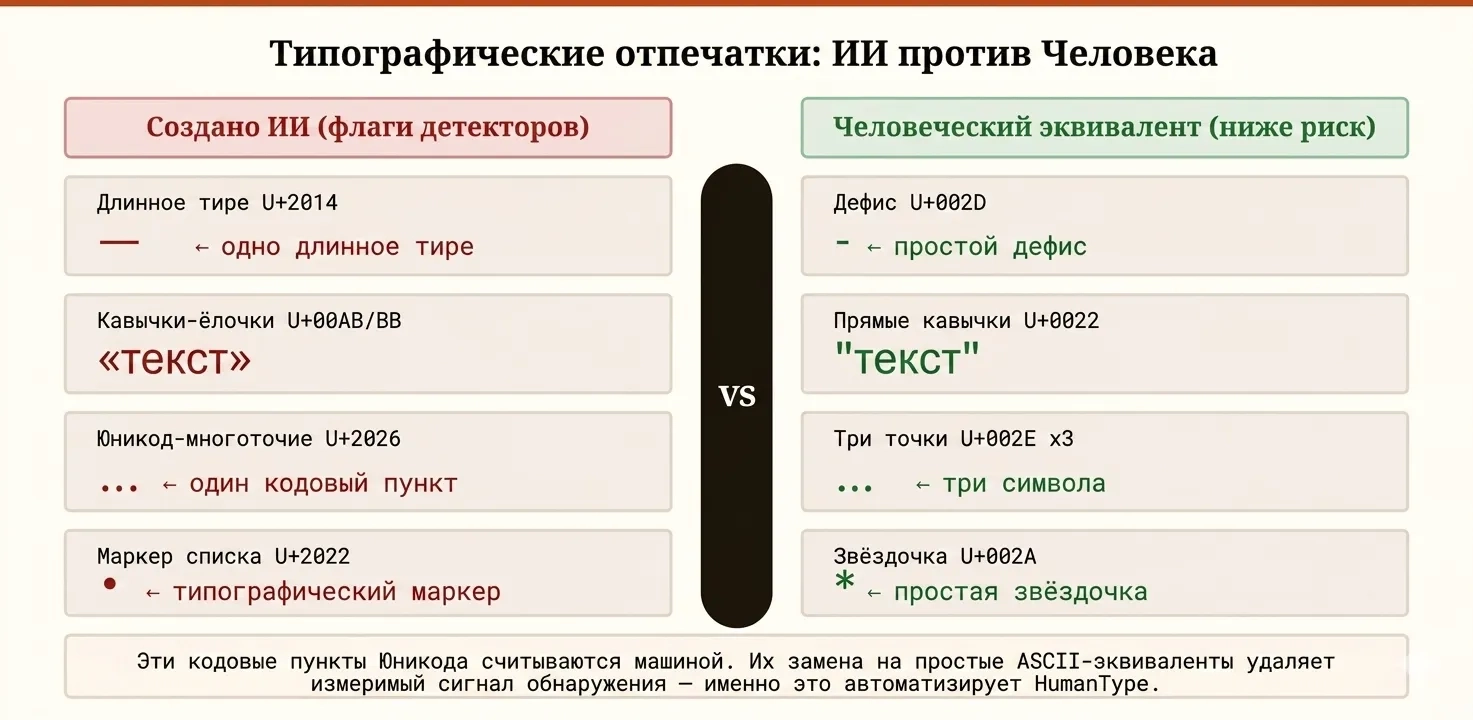
В неформальных тестах с различными текстами замена типографских символов в ИИ-сгенерированных материалах на их ASCII-эквиваленты может заметно снизить оценку детекции — хотя эффект варьируется в зависимости от конкретного детектора и длины текста. В сочетании с другими методами нормализация типографики является одним из наиболее системных первых шагов именно потому, что она нацелена на конкретный, машиночитаемый сигнал, а не на нечто абстрактное вроде «голоса автора».
Что на самом деле измеряют детекторы
- Перплексия: Насколько языковая модель «удивляется» каждому слову. Человеческий текст имеет более высокую перплексию (больше вариативности), тогда как ИИ-текст более предсказуем. Низкая перплексия — ключевой сигнал обнаружения.
- Бёрстинесс: Вариативность длины и сложности предложений. Люди естественно чередуют короткие и развёрнутые предложения. ИИ склонен создавать структурно однородные конструкции. Низкий бёрстинесс — сигнал для большинства детекторов.
- Типографские отпечатки: Наличие конкретных Unicode-символов — длинных тире, фигурных кавычек, символа многоточия, — которые статистически переставлены в ИИ-обучающих данных по сравнению с повседневным набором текста.
- Статистические аномалии: Необычное распределение частотности слов, редкие токены и другие математические паттерны, отклоняющиеся от типичного человеческого письма.
- Согласованность и структура: Некоторые детекторы штрафуют за непривычно последовательную структуру абзацев или аргументации, которая может свидетельствовать о машинной генерации.
Сравнительная таблица детекторов
Основные коммерческие детекторы различаются по методологии, стоимости и подходу к пограничным случаям. В таблице ниже представлены публично заявленные характеристики; независимая точность варьируется в зависимости от типа текста и обновляется по мере выхода новых версий.
| Детектор | Основные сигналы | Бесплатный доступ | API | Особенность |
|---|---|---|---|---|
| GPTZero | Перплексия, бёрстинесс, поабзацный анализ | Да | Да | Более высокий процент ложных срабатываний для текстов не на родном языке (по данным независимых исследований) |
| Originality.ai | Перплексия, проверка фактов, читаемость | Нет (кредитная система) | Да | Оптимизирован для веб-контента; менее протестирован на академических текстах |
| Turnitin AI | Перплексия, поведенческие паттерны письма | Только для учреждений | Нет (интеграция с LMS) | Результаты носят рекомендательный характер; Turnitin явно предупреждает о недопустимости их использования как единственного доказательства |
| Sapling AI | N-граммовая вероятность, стилистические паттерны | Да (ограниченно) | Да | Чувствителен к формальному регистру даже в человеческих текстах |
| Writer.com детектор | Перплексия, распределение токенов | Да | Да | Преимущественно откалиброван под маркетинговые и деловые тексты |
Кейс: что даёт нормализация типографики
Для наглядности рассмотрим короткий абзац эссе, созданный языковой моделью. Сырой вывод содержит длинные тире, фигурные кавычки и символ многоточия Unicode — всё это стандартно для ИИ-вывода. При прогоне через типичный детектор статистический отпечаток хорошо считывается.
После замены только Unicode-символов на простые ASCII-аналоги (без каких-либо изменений слов или структуры) типографский сигнал устраняется. Абзац идентичен по смыслу и формулировкам — изменилась лишь кодировка на уровне символов. В результате один измеримый сигнал — типографский отпечаток — ликвидируется, что, как правило, в той или иной мере снижает общую оценку детекции. Степень снижения варьируется в зависимости от детектора и длины текста.
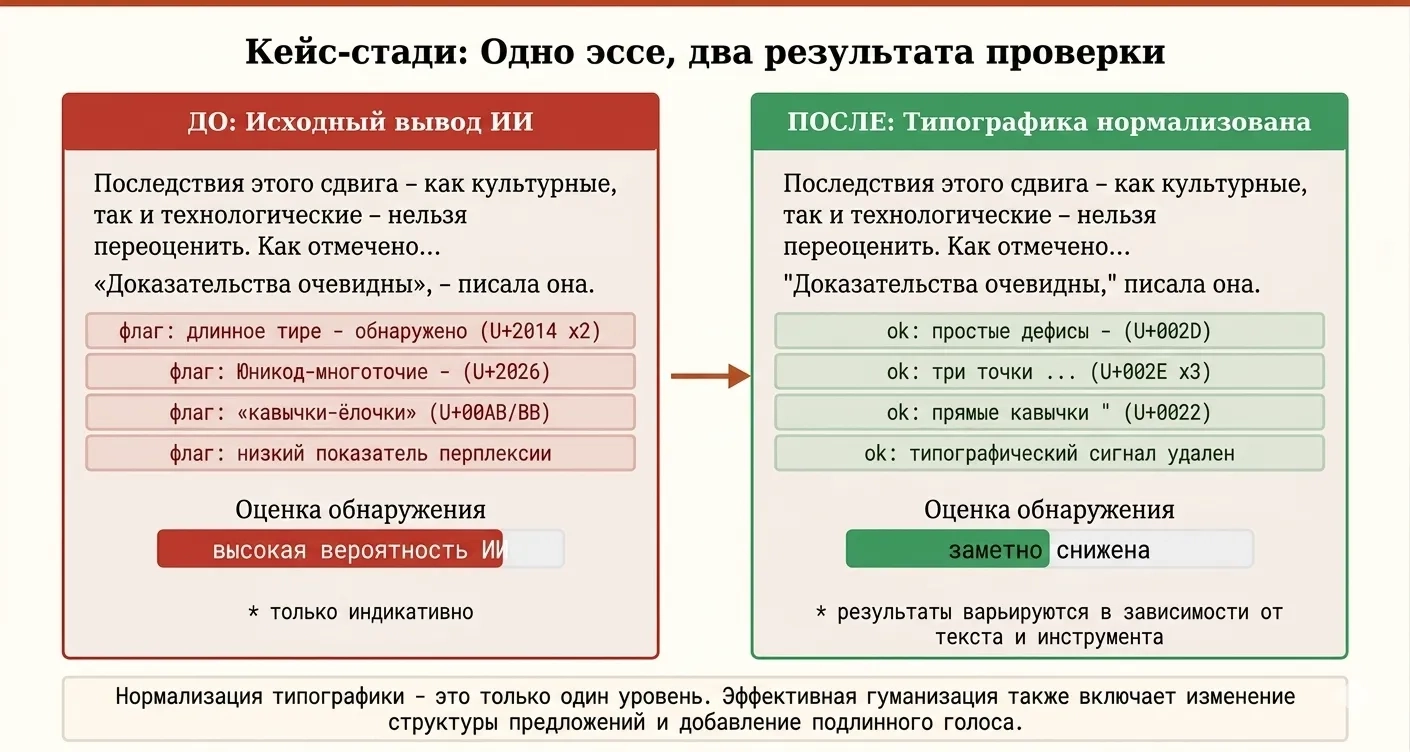
Этот кейс также демонстрирует ограничения подхода: нормализация типографики не затрагивает перплексию и бёрстинесс. Для этих сигналов необходимо менять саму структуру текста — варьировать длину предложений, переставлять аргументы, намеренно добавлять неоднородность там, где это уместно. Типографика — самый простой слой для систематической и автоматической обработки; всё остальное требует редакторских усилий.
Итог
Детекторы ИИ — полезные инструменты скрининга, но не непогрешимые судьи. Они измеряют статистические прокси для ИИ-авторства, и у этих прокси есть известные погрешности. Ложные срабатывания — документально подтверждённая проблема, особенно для определённых стилей письма и авторов-неносителей языка. Оценки детекции следует рассматривать как вероятностные сигналы, а не как вердикты.
Снижение оценок обнаружения требует многоуровневого подхода: нормализации типографики, вариации структуры предложений, добавления мелких несовершенств и придания тексту личного голоса. Это не уловки — это те же техники, которые отличают хорошее, разнообразное письмо от излишне отполированной однородности, характерной для большинства ИИ-вывода.
Читайте наше полное руководство по типографской нормализации — HumanType берёт на себя типографский уровень, остальное за вами.
Источники и дополнительное чтение
- Liang et al. (2023). "GPT detectors are biased against non-native English writers." Patterns, Cell Press. doi.org/10.1016/j.patter.2023.100779
- Sadasivan et al. (2023). "Can AI-Generated Text be Reliably Detected?" arXiv preprint. arxiv.org/abs/2303.11156
- Turnitin (2023). AI Writing Detection: Guidance for Educators. Turnitin LLC. turnitin.com/solutions/ai-writing
- Gehrmann et al. (2019). "GLTR: Statistical Detection and Visualization of Generated Text." ACL 2019. aclanthology.org/P19-3019